
De la dictée au compte rendu : speech‑to‑text et LLM
Avant d’analyser le discours clinique, l’IA doit d’abord franchir une étape décisive : transformer la voix en texte. Pour cela, elle s’appuie tout d’abord sur un modèle de reconnaissance vocale, qui combine deux sous‑composants : un modèle acoustique, chargé de reconnaître les sons et les phonèmes à partir du signal vocal, et un modèle de transcription, qui remet les mots dans le bon ordre et corrige les ambiguïtés liées à la prononciation ou au bruit ambiant (fig. 1b). Ensemble, ces deux éléments permettent aujourd’hui d’obtenir une transcription fiable, même si le praticien parle vite ou dans un environnement bruité [1]. Une fois ce texte généré, il est pris en charge par un modèle d’interprétation, un modèle de langue de grande taille (LLM) qui ne se contente plus de convertir des sons en mots, mais cherche à en saisir le sens général, l’intention du praticien et le contexte clinique (fig. 1c). À partir de ces éléments, le modèle organise les informations et génère un document de synthèse adapté au besoin : compte rendu, courrier au confrère ou consignes pour le patient par exemple.
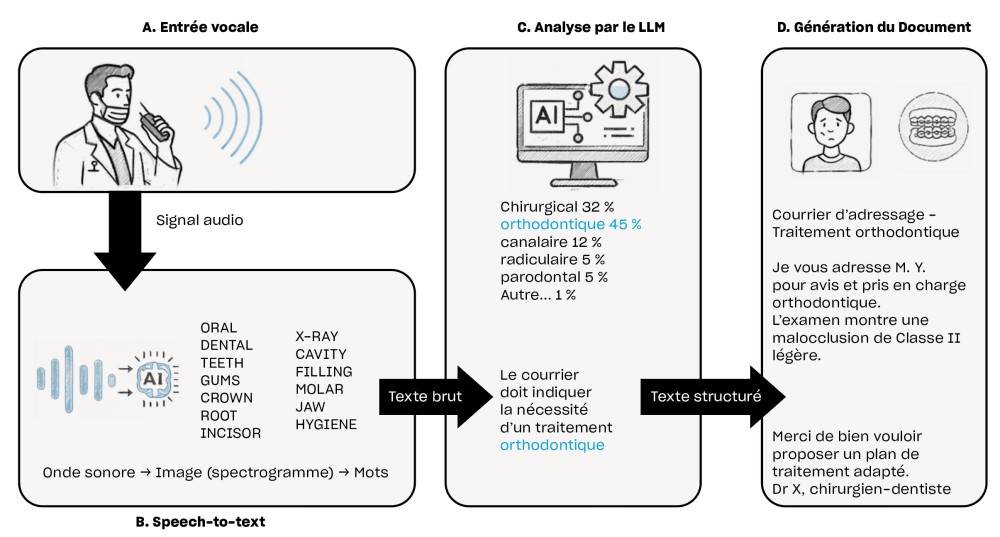
Du texte aux actions personnalisées : l’intelligence du LLM
Une fois le texte brut obtenu, il devient possible de lui donner différentes formes selon le besoin clinique, tel que la rédaction d’un compte rendu interne au cabinet, d’un courrier de correspondance ou encore des consignes post-opératoires. Le modèle d’interprétation va alors analyser le sens général de la dictée, mettre en avant les éléments cliniques pertinents et les organiser en fonction du contexte choisi par l’utilisateur. Cette capacité d’adaptation repose en partie sur l’approche dite d’extraction « zero‑shot », qui correspond à la faculté du modèle à réaliser une tâche qu’il n’a pas spécifiquement apprise [2]. Grâce à cette flexibilité…





